amazon.co.jpのカテゴリランキング情報収集方法
amazonを利用するとはどういうことか?
というちょっと小難しいところから入りたいと思います。
ご存じかとは思いますが、amazon.co.jpでお買い物をするためにはログインが必要で、ログイン時に下記メッセージが表示されます。
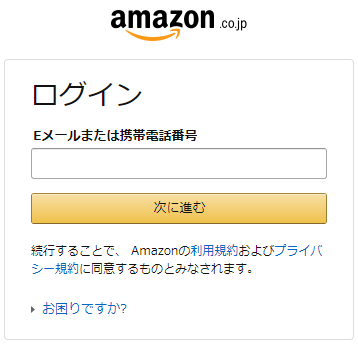
ポイントは「続行することで、Amazonの利用規約およびプライバシー規約に同意するものとみなされます。」とあります。すなわち、ログインしなくても収集できる情報については、利用規約に同意しない状態でも参照することが可能。と解釈できます。
利用規約のほうに、下記のような記載があります。

データマイニングや、ロボットなどのデータ収集・抽出ツールの使用は認められません。
すなわち、ログインしたうえで(利用許諾に同意したうえで)しか得られない情報をマイニング、スクレイピングで収集することは、利用許諾への違反となるのでNG。ただし、利用許諾に同意しない状態でも収集できるデータをマイニング、スクレイピングで収集しても、利用許諾違反にはならない(そもそも同意もしていない)と判断できます。
すなわち、ログインしたうえで(利用許諾に同意したうえで)しか得られない情報をマイニング、スクレイピングで収集することは、利用許諾への違反となるのでNG。ただし、利用許諾に同意しない状態でも収集できるデータをマイニング、スクレイピングで収集しても、利用許諾違反にはならない(そもそも同意もしていない)と判断できます。
当然、マイニング、スクレイピングでAmazonさんのサーバーに負荷をかけてサービスが立ちいかなくさせてしまったり、収集したデータをむやみやたらに公開してしまったりすると、別の観点で問題が出てきますので、節度を守って利用する必要があると考えます。
※例えば、収集したデータの著作権はそもそも誰のもの?それを勝手に公開などしていいの?など。サーバー負荷が高まってしまえば、DOS攻撃とみなされても仕方ないですし。
ちなみに「マイニング、スクレイピングの処理をAWSで動かして自動収集!」と考える方もいらっしゃるかと思いますが、類似の利用規約があると考えますので(上記の利用規約に何らかの形で同意してしまっている)、よく確認してから実施されるのがいいと思います。
またいわゆる免責事項ですが、こちらの考え方を参考にされて何らかのアクションを実施された結果、Amazonさんから注意された、怒られた、損害賠償求められた、というケースが発生し得る可能性ありますが、当方は一切関知いたしません。
あくまで自己判断の上でご利用ください。
ということで、本題。
amazon.co.jpでランキング情報を収集してみる
ITガジェット好きにとって、どんなITガジェットが流行ってるのか?は常に気になるものです。そこで、amazon.co.jpのカテゴリ毎ランキング情報を収集するスクリプトを組んでみました。
※今回スクリプトを組むにあたってこちらのサイトを参考にさせていただきました。
urllibがなく、urllib3を使う必要があったり、urllib.requestではなく、PoolManagerを使うなど変更してます。
#!/usr/bin/python
import urllib3
from bs4 import BeautifulSoup
import time
import datetime
import pandas as pd
uri = 'https://www.amazon.co.jp/'
category = 'computers'
browse_node_id = '7987084051'
info = []
def ama(url):
#obtain each page as html.
http = urllib3.PoolManager()
html = http.request('GET', url)
soup = BeautifulSoup(html.data, 'lxml')
time.sleep(2)
return soup
def get_info(ele):
# pickup rank, title, URL, picture URL, price as dictionary style.
if ele.find("span", class_="p13n-sc-price") == None:
return
info = {
"rank": ele.find("span", class_="zg-badge-text").string.strip(),
"title": ele.find_all("div", class_="p13n-sc-truncate")[0].string.strip(),
"url": "https://www.amazon.co.jp" + ele.find_all("a", class_= "a-link-normal")[0].attrs["href"],
"img": ele.find_all("img")[0].attrs["src"],
"price": ele.find("span", class_="p13n-sc-price").string.strip()
}
return info
for n in range(1,2):
url = uri + 'gp/bestsellers/' + category + '/' + browse_node_id + '/' + '?pg=' + str(n)
soup = ama(url)
i = 1
for ele in soup.find_all("li", class_="zg-item-immersion"):
info.append(get_info(ele))
i = i + 1
if i > 20:
break
today = datetime.datetime.now().strftime('%Y.%m.%d')
#output as csv by using panda.
df = pd.DataFrame(info)
df.to_csv('Amazon' + str(today) + '.csv',encoding='utf-8_sig')
ここでは、NASカテゴリのランキング情報が取得できるようにURLを設定してみました。
Windows 10のWSL環境を使ったUbuntu(改めて見てみると、18.04。ちょっと古いですね。)で実行すると、下記のようにデータを取得できます。
Windows 10のWSL環境を使ったUbuntu(改めて見てみると、18.04。ちょっと古いですね。)で実行すると、下記のようにデータを取得できます。

カテゴリを変えるなどすることで、これで簡単にはやりのガジェットを確認するすべができました!
まとめ
流行りのガジェット情報を入手するための手段として、ランキング情報を取得するスクリプトを作成してみました。
これで、いちいちブラウザを開いてサイトを直接確認することなく、新しいガジェットを確認することができますね♪

コメント
コメントを投稿